Christina Koch, University of Wisconsin – Madison, August 30, 2018
Collaborating with research computing facilitators and a broader team of software developers, systems administrators, and project administrators, biostatistics researchers studying personalized medicine were able to perform large scale data analysis on restricted medical data using the Center for High Throughput Computing’s (CHTC’s) shared computational resources, allowing them to focus on exploring their research questions without needing to worry about computational limitations.
The Objective
David Page is a faculty member in the Biostatistics and Medical Informatics department at University of Wisconsin-Madison. He and Lauren Michael, one the research computing facilitators at the Center for High Throughput Computing (CHTC), had an initial meeting to discuss a project in personalized medicine involving the analysis over a million health records, encompassing millions of diagnoses, lab results, and procedures that can be used to predict thousands of possible types of future diagnoses or other medical events. This research could then be taken back to the clinic, where an analysis of an individual patient’s health history could indicate whether they were at risk for a particular disease.
Computation is a crucial component in these research efforts to improve health care. The project’s main computing method was machine learning, which involves sampling large quantities of data and then running iterative statistics and matrix calculations. These computations need to be run many times in order to calibrate the machine learning model to be as accurate as possible, and each computation can grow in length based on the size of the input data.
Using CHTC’s computational resources to meet these computational needs would allow the project to realize its initial goals of determining patient risk for a few common diseases, and then potentially run larger experiments, like the risk for a larger pool of diseases and comparing different disease types.
The privacy and security restrictions placed on the project’s data were challenges standing in the way of using CHTC resources. These data consisted of millions of electronic health records, which had been anonymized (names removed), but by their nature as health records, could not be completely de-identified. Based on initial conversations, it was clear that extra security measures would be needed to use these data in CHTC and abide by the terms of the project’s data use agreement. It was therefore necessary to identify what would be required to use the project data in CHTC and then take actions to make that happen.
Several groups were needed to make this outcome possible — the university’s office of Research and Sponsored Programs (RSP); PI David Page and two of his students, Ross Kleiman and Paul Bennett; CHTC facilitators Lauren Michael and Christina Koch; HTCondor developers Todd Tannenbaum and Zach Miller; and the rest of the CHTC operations team, including lead systems administrator Aaron Moate.
The Solution
Conversations with the RSP Office indicated that there were three primary concerns that needed to be addressed in order to use the project data in CHTC:
- Data had to be used on servers that were physically located in specific areas, controlled by CHTC.
And, when on the system, the data had to either:
- Be on a server only accessible to members of the project, or
- If on a server shared by other people, the data needed to be encrypted.
Thus, the solution for using the project data on CHTC had multiple pieces. Addressing the first concern, the servers’ physical location, was easy because CHTC servers are in four rooms in two buildings, with access limited to a known set of staff members.
Two approaches were taken to address the second and third concerns. Data used in CHTC almost always exists in multiple places. First, it is placed on the “submit node” (where multiple users log in and submit jobs to the system), so that it is ready to be used. And second, pieces of data are transferred to different “execute nodes” (where jobs actually run), as needed for specific jobs. Any solution for the Page group was going to involve controls at each type of location.
For data on the submit node, there was a pre-existing solution that could be used. CHTC already had a policy where individual faculty members can buy a submit node that is only accessible by their group, but is run and administered by CHTC staff. As David had the funds to purchase a server, this was a straightforward way to ensure that the data on the submit node would only be accessible to group members and select CHTC staff.
However, for the execute nodes, the jobs from this project would almost certainly be sharing compute nodes with other non-project jobs, and so encryption would be needed. Because of the close relationship between CHTC’s compute resources and the HTCondor job scheduler (developed at CHTC), encryption features were added to HTCondor. For this project, the options to encrypt a job’s working directory and its transfer of files were added.
Beyond these technical arrangements, an important component of the whole process was building relationships between CHTC staff (facilitators, developers, administrators) and the project members (PI, students). After the initial setup was in place, the students working on the project found that preparing the data for transfer to jobs was a severe bottleneck in the process, severely limiting the number of submitted jobs. By talking to Christina, Lauren and HTCondor developer Zach Miller, together everyone found a solution that overcame this bottleneck (a RAM disk in their submit node), coordinated the purchase of the disk, and then installed and used it. The relationships that had been built during the process of handling data securely were therefore able to help the group solve a different problem (the data bottleneck) quickly and efficiently.
The Result
Being able to support this project on CHTC meant that the researchers involved were able to use vast amounts of computing (their largest experiment used a century of CPU time!) without needing to buy or run their own computers. This in turn enabled them to do better research. Rather than focusing on a single disease, they have been able to explore the broad landscape of all diseases through the scalability afforded by CHTC. By looking at all diseases they have been able to ask and answer large-scale research questions such as: which diseases are the most difficult to predict? And, what factors are most useful in predicting disease in general? Not only has the computation in CHTC allowed them to look at more individual diseases, but they are beginning to understand the ways in which various diseases are similar to, or different from, one another.
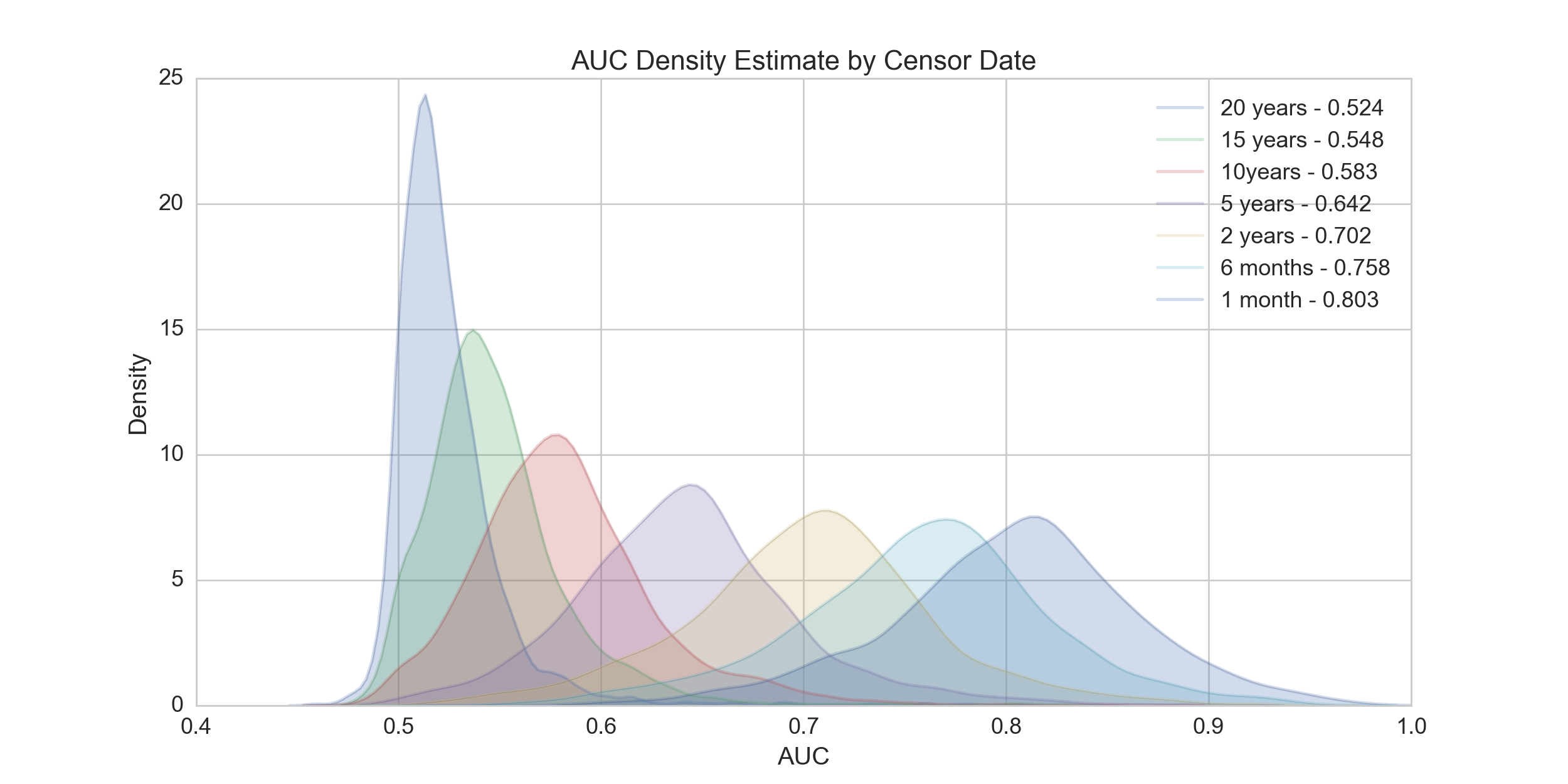
Beyond the specific research results, this project taught the CHTC team valuable lessons about how to support a project with specific data needs. In particular, the encryption features added to HTCondor are useful in other contexts, including jobs that need passwords or keys, have export-controlled data/software, or otherwise use data that cannot be shared publicly.
Collaborators and Resources
- David Page, Professor, Biostatistics and Medical Informatics / Computer Sciences, UW Madison
- Ross Kleiman, graduate student, Computer Sciences, UW Madison
- Paul Bennett, graduate student, Computer Sciences, UW Madison
- Lauren Michael, Research Computing Facilitator, CHTC, UW Madison
- Christina Koch, Research Computing Facilitator, CHTC, UW Madison
- Aaron Moate, Systems Administrator, CHTC, UW Madison
- Todd Tannenbaum, Software Developer – HTCondor, CHTC, UW Madison
- Zach Miller, Software Developer – HTCondor, CHTC, UW Madison