Need for hybrid MPI-OpenMP programs
The multi-core era is here and our programming habits need to adjust to it. Most people by now have their codes parallelized using MPI for distributed memory machines, as that era has been upon us for 20 years now. MPI codes can work well on multi-core machines, but, with the increasing core counts, there is more pressure for splitting the work inside of the MPI tasks. The most natural way to do that is to use OpenMP to introduce thread parallelism.
Programs that use both MPI and OpenMP are sometimes called hybrid parallel codes, and map well onto distributed multi-core machines. All major compilers these days support OpenMP (which is a C and Fortran programming language extension – as opposed to MPI which is a programming library independent of the programming language standard). There are a number of MPI implementations which are thread-safe – that is allow for communication from inside of the threads. But about this some other time. Most hybrid MPI-OpenMP programs thread parallelize computation kernels that don’t communicate, the communication is done in a thread serial part. My example gravity and magnetics inversion code does this as well.
“Naive” program launch – no CPU affinity
One then runs the MPI-OpenMP program as before with no threads, but now adding the OMP_NUM_THREADS environment variable to specify how many OpenMP threads to use, e.g.
mpirun -np 4 -genv OMP_NUM_THREADS 6 ./inversion
We typically map two MPI tasks per node, as this is a natural mapping for the common dual-CPU-socket compute nodes in our clusters. In this example, I am using 12 core dual socket nodes (2×6 core CPUs) of the relatively old Intel Westmere generation.
The inversion code splits 3D domain into equal chunks and iteratively does some calculation, followed by MPI_Allreduce calls to collect the data. In this particular case, all MPI tasks do the same amount of work, so, one would expect them to run the same time, and MPI have minimal performance impact (the MPI_Allreduce only reduces relatively small arrays). And indeed, on some hardware, the program scales fairly well (I always recommend to do a simple scaling analysis of a program to do basic assessment on how well it performs). But, on the Westmere nodes, I noticed a variation in runtime for different runs of the same problem size.
When I run the program in the Allinea Map profiler using the typical mpirun command listed above, I get the following timeline profile:
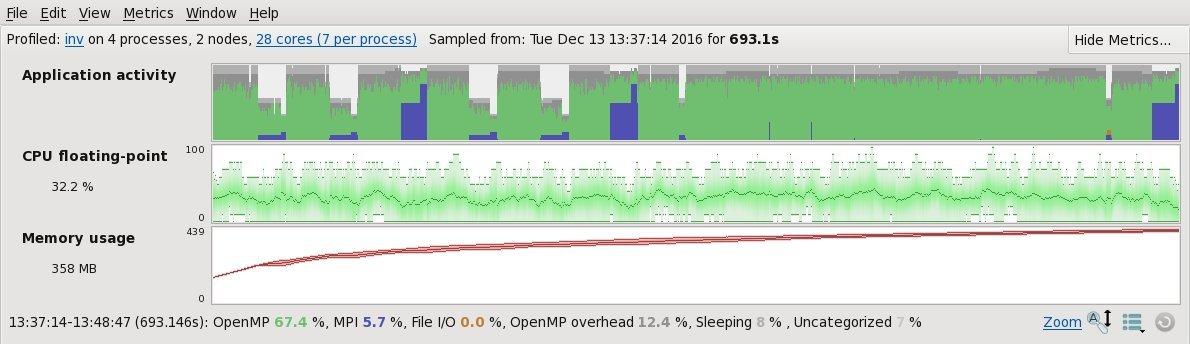
The striking part are the purple chunks in the topmost timeline which denote time spent in MPI operations. As there is not much communication in the code, MPI time should be near zero, and it’s 5.7%. The first thing that comes to mind is the NUMA data locality, for details on NUMA, see https://en.wikipedia.org/wiki/Non-uniform_memory_access. In short, it may take longer to access the data in the memory from one CPU than the other, thus putting the MPI tasks out of sync. We can see that in the timeline profile, some MPI tasks are waiting for others to finish at the collective MPI operations, which makes it look like the time is spent doing communication. Instead, the MPI tasks that are faster are waiting at the MPI call for the other tasks to finish.
CPU affinity on the MPI task level
At this point I am assuming that the issue is NUMA, so, to ensure that MPI tasks are accessing only memory on its own socket, I can try to pin the MPI task to the CPU socket. Some more info on CPU pinning is here: https://en.wikipedia.org/wiki/Processor_affinity.
Most MPI distributions allow locking the task to that socket (or CPU core, if running MPI only program). MPICH does it with the flag “-bind-to socket”. We also want to ensure even distribution of tasks to sockets, so, we also add flag “-map-by socket”. Thus, our MPI execution line now goes as:
mpirun -np 4 -genv OMP_NUM_THREADS 6 -bind-to socket -map-by socket ./inversion
The Allinea Map profile is below:

Things got worse. The program took longer to run and time in MPI has increased as well. So, while NUMA may be an issue, it’s not the main culprit. We have pinned the MPI tasks to CPU sockets, but, let the many OpenMP threads that each MPI task launches freely move among the cores of the socket. Most multi-core CPUs these days have hierarchical cache memory, so, migration of threads across all the socket cores may be detrimental to efficient cache use. There’s a good description on OpenMP pinning here: http://www.glennklockwood.com/hpc-howtos/process-affinity.html. It is a great read especially for the graphical description of ways how to distribute threads on cores, but, it does not provide a flexible solution for MPI/OpenMP hybrid codes.
So, the next step is to pin the OpenMP threads to CPU cores, one thread per one code. Intel OpenMP has the most flexible way how to achieve this with its KMP_AFFINITY environment variable (Intel Compiler 17 info is here: https://software.intel.com/en-us/node/684320).
To pin each thread to a core, we use do the following:
mpirun -np 4 -genv OMP_NUM_THREADS 6 -genv KMP_AFFINITY "granularity=fine,compact,1,0" -bind-to socket -map-by socket ./inversion
The Allinea Map profile now looks like this:

The time spent in MPI (waiting) is gone, and OpenMP utilization has improved as well. Our code is now running about 30% faster than before without making any modification to the program, or even recompiling it.
One may ask, this looks great for MPICH and Intel OpenMP, but how about other MPIs or other compilers (GNU, PGI)? And how can I tell what task affinity my program uses?
MPI, OS and compiler affinity support
As for MPIs, I have talked about this earlier here: https://www.chpc.utah.edu/documentation/software/mpilibraries.php. In short, Intel MPI tries to do the correct task to CPU pinning automatically and is generally good at it. MPICH does not pin at all by default so one has to use the pining flags. MVAPICH2 is trying to do this automatically but it does not work for MPI/OpenMP codes. Turning off the MVAPICH2 affinity and using MPICH mpirun flags works. OpenMPI uses similar flags as MPICH (and I never bothered to find what’s the default as I don’t use it much).
The OS has several tools that can query and set thread affinity, namely the “numactl” and “taskset” commands. In my experience, both commands are useful for checking things, but complicated to use to set the affinity. There are numerous posts online on how to use these commands that I find marginally useful. The OpenMP environment variables are an easier way to go.
As for OpenMP compilers settings, Intel stands out with its KMP_AFFINITY variable flexibility, which works well for common situations. Both GNU, and PGI also have flags that control pinning threads to cores, but, one has to list the core IDs explicitly. This is not very different from what the OS “taskset” command would do. GNU has variable GOMP_CPU_AFFINITY, detailed here: https://gcc.gnu.org/onlinedocs/libgomp/GOMP_005fCPU_005fAFFINITY.html#GOMP_005fCPU_005fAFFINITY, and PGI has similar variable called MP_BLIST (with a very short paragraph in their user manual not even worth referencing here). But average HPC user will not be wanting to spend time writing a script that creates the core lists to feed to these environment variables.
This can get even more complicated if we want to run more than two MPI tasks per node. I suspect this situation will become more common with increasing CPU core counts. From what I can tell, even KMP_AFFINITY does not have built in logic to deal with this situation, so, explicit thread pinning is necessary for Intel OpenMP as well.
Assigning MPI/OpenMP core affinity through a script
After a fruitless search to find something that would create explicit core map for each MPI task, I wrote a script that tries to do that, called “pinthreads.sh“. This script produces a core map for each MPI task provided that there’s one or more MPI task per socket and the number of available cores for each MPI task is the same. For example, on a 20 core dual socket node, 4 tasks 5 threads/tasks is OK but 5 tasks 4 threads/task is not OK as we don’t have the same number of tasks on each socket.
To run this and pin each OpenMP task to a separate core, we modify the mpirun command as:
mpirun -np 4 -genv OMP_NUM_THREADS 6 -bind-to socket -map-by socket ./pinthreads.sh ./inversion
Here we launch the pinthreads.sh via the mpirun followed by the ./inversion executable (and its potential arguments) as an argument to the script. The script then creates and outputs the core map for each MPI task, sets the GOMP_CPU_AFFINTY (for GNU and Intel – Intel supports this variable too) and MP_BLIST (for PGI) environment variables and calls the actual executable to run the program. Before launching the executable, the pinthreads.sh will report something like this:
MPI rank 0 maps to cores 0,1,2,3,4,5,12,13,14,15,16,17
MPI rank 1 maps to cores 6,7,8,9,10,11,18,19,20,21,22,23
MPI rank 3 maps to cores 6,7,8,9,10,11,18,19,20,21,22,23
MPI rank 2 maps to cores 0,1,2,3,4,5,12,13,14,15,16,17
Looking at what cores each task uses can be done with the following bash command:
for i in $(pgrep inversion); do ps -mo pid,tid,fname,user,psr -p $i;done
PID TID COMMAND USER PSR
10301 - inversion u0101881 -
- 10301 - u0101881 6
- 10305 - u0101881 20
- 10306 - u0101881 7
- 10307 - u0101881 8
- 10309 - u0101881 9
- 10312 - u0101881 10
- 10313 - u0101881 11
PID TID COMMAND USER PSR
10302 - inversion u0101881 -
- 10302 - u0101881 0
- 10303 - u0101881 14
- 10304 - u0101881 1
- 10308 - u0101881 2
- 10310 - u0101881 3
- 10311 - u0101881 4
- 10314 - u0101881 5
Here we have 7 threads per task, 6 are the OpenMP threads with the correct core locality, the last one is the Intel OpenMP master thread. To check the correct pinning, we expand this bash one liner a bit further:
for i in $(pgrep inversion); do for tid in $(ps --no-headers -mo tid -p $i |grep -v -); do taskset -cp "${tid}"; done ;done
pid 11242's current affinity list: 0
pid 11244's current affinity list: 0-5,12-17
pid 11245's current affinity list: 1
pid 11246's current affinity list: 2
pid 11250's current affinity list: 3
pid 11252's current affinity list: 4
pid 11254's current affinity list: 5
pid 11243's current affinity list: 6
pid 11247's current affinity list: 6-11,18-23
pid 11248's current affinity list: 7
pid 11249's current affinity list: 8
pid 11251's current affinity list: 9
pid 11253's current affinity list: 10
pid 11255's current affinity list: 11
The output confirms that we are pinning correctly the worker OpenMP threads, and the Intel OpenMP master thread can float over all the cores of the CPU socket.
This output can be contrasted with the output with no pinning at all, e.g.:
pid 11392's current affinity list: 0-23
or with pinning just on sockets, e.g.:
pid 11334's current affinity list: 0-5,12-17
If we use more than two MPI tasks per node, the core list is built by pinthreads.sh accordingly:
mpirun -np 8 -genv OMP_NUM_THREADS 3 -bind-to socket -map-by socket ./pinthreads.sh
MPI rank 6 maps to cores 3,4,5,15,16,17
NUMA core mapping is sequential and hyperthreading is on
MPI rank 5 maps to cores 6,7,8,18,19,20
MPI rank 7 maps to cores 9,10,11,21,22,23
MPI rank 2 maps to cores 3,4,5,15,16,17
MPI rank 4 maps to cores 0,1,2,12,13,14
MPI rank 0 maps to cores 0,1,2,12,13,14
MPI rank 3 maps to cores 9,10,11,21,22,23
MPI rank 1 maps to cores 6,7,8,18,19,20
Conclusions
There still is not an easy way for pinning MPI processes and OpenMP threads to CPU sockets and cores. In this article I tried to show why we should be paying attention to it, and how to do it for different MPI and OpenMP implementations. I also present a script that should be helpful in doing correct task and thread pinning with varied MPI task and OpenMP thread count.